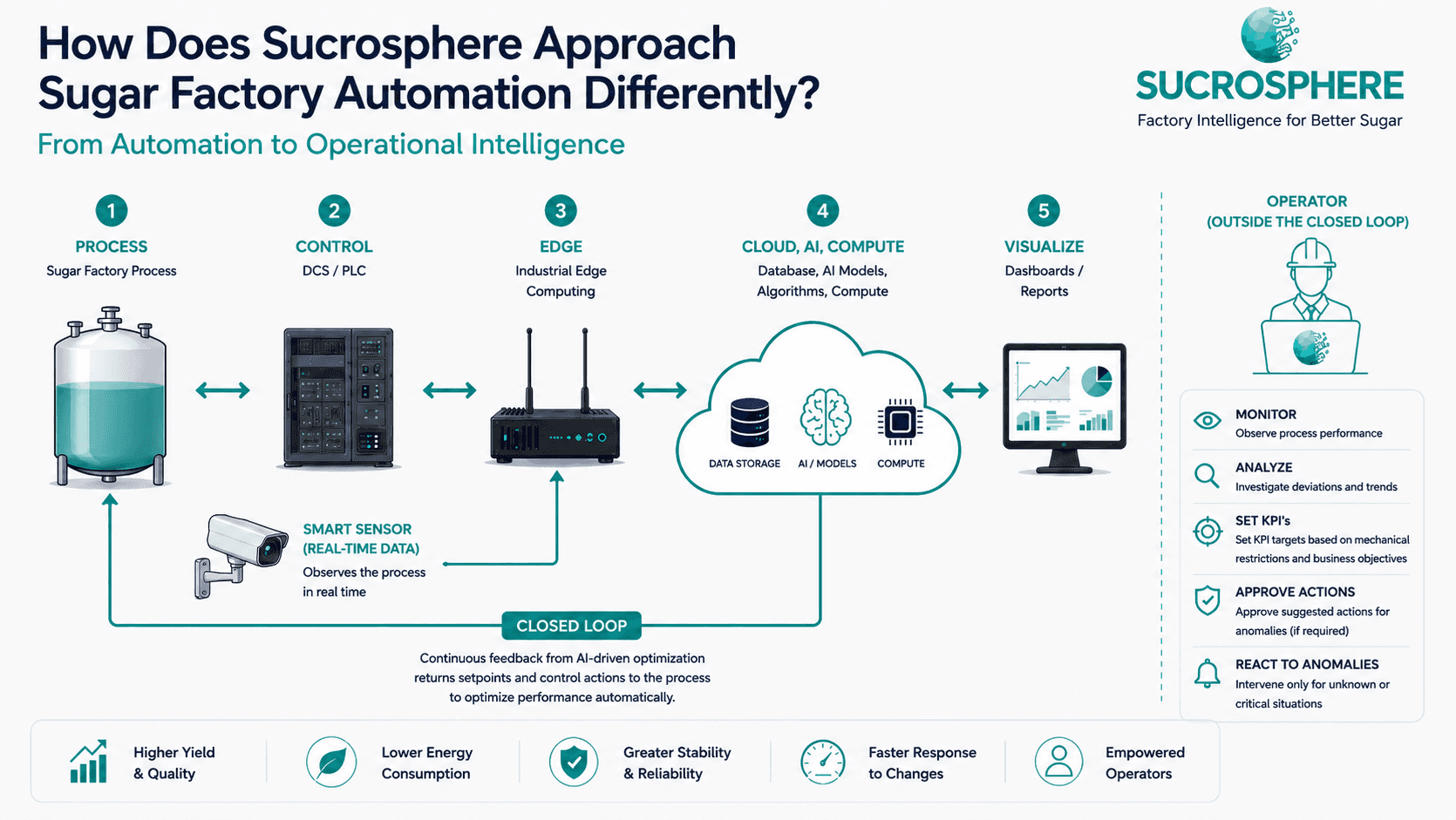
An MPC-integrated logic that turned every manual operator adjustment per pressure event into zero — through the worst conditions of the campaign.
Frozen beet. Cold weather. The last two weeks of the campaign. Across the industry, this is when extraction towers misbehave — when cossette quality degrades, fines accumulate on the bottom sieve, juice can't escape, and pressure climbs. Operators know what comes next: a high-pressure alarm, a scramble across multiple set-points, and on the bad days, a multi-hour tower emptying that nobody wants to explain on Monday.
Until recently, the response to overpressure depended almost entirely on operator experience — on which shift was running and how that crew had learned to react. There was a single high-pressure alarm raised on the DCS with no guidance, no systematic recovery path back to MPC, and a long list of manual adjustments expected per event, sometimes including reductions or full stoppages of the upstream slicing line. If the situation persisted, the consequences compounded, and in severe cases the tower had to be partially or fully emptied to clear the blockage. A permanent fix had been wanted for several campaigns.
We took a different position. Pressure events are not failures of the operator — they are a control problem the controller should solve. So we built one. An automated pressure protection and recovery logic, integrated directly into our MPC layer, that catches excursions early, applies graduated corrective actions, and hands control back the moment the process is stable.
Why Pressure Is the Hardest Part of Extraction
The primary cause of overpressure inside a beet extraction tower is sieve clogging. When cossettes are poorly sliced, too thin, or degraded — common with frozen beet at the end of campaign — they don't move uniformly. Fine particles and over-macerated material accumulate on the bottom sieve, restricting juice outflow. Juice can't exit, pressure builds, and the process drifts away from its operating point.

The disturbance is inherently uncontrollable upstream. Cossette quality depends on harvest, storage, weather, and slicing quality. So the question isn't how to prevent the disturbance — it's how to absorb it without disrupting production. That's a control problem, not an operator problem. And it's a problem that punishes any approach with a long reaction time, because tower pressure can rise sharply within minutes once the sieve starts to clog.
Manual Response vs. Automated Logic
Replacing operator response with structured automation changes every aspect of how a pressure excursion is handled.
| Aspect | Manual Response | Automated Pressure Logic |
|---|---|---|
| Trigger | Single high-pressure alarm with no guidance | Graduated thresholds with defined response per zone |
| Response time | Minutes — depends on shift, attention, and experience | Seconds — runs continuously inside MPC |
| Operator actions per event | Many manual adjustments, sometimes including slicing reduction or stoppage | Zero — events resolved silently in the background |
| Consistency between operators | Low — experience-dependent, varies by shift | 100% — same response every time |
| Recovery path | None defined; operator decides when to release | Stepwise juice recovery + automatic MPC handback |
| Worst-case outcome | Multi-hour tower emptying and refill | Structured DCS escalation only as last resort |
How the Logic Works
Graduated Response
The logic uses two pressure thresholds, not one. Above the operational upper bound, it activates a minimum corrective action, if it works an informatory message tells the operator the logic is working — without demanding action. Only if pressure crosses the second bound does the system enter into emergency mode according to the extraction tower manufacturers SPO. While these corrections are applied, every other process variable is tracked continuously to confirm it stays inside its operating range, so pressure is never relieved at the cost of another constraint being violated.
Automatic Recovery
Most pressure protection systems, once they fire, leave the process in a degraded state until somebody resets it. This one doesn't. After each corrective action and a short stabilisation wait, the logic checks whether pressure has dropped back below the operational bound. If it has, it begins a controlled recovery — restoring juice in small stepwise increments, verifying stability after each one, and only closing the event once flow is safely back to its pre-event level. Throughout the recovery, the logic keeps every other process variable inside its bounds, so pressure relief is never traded for a problem somewhere else. No operator reset, no degraded operating point.
MPC-First
The most important design choice was where authority lives. Many protection layers default to handing control to the DCS the moment something goes wrong, which means MPC has to be reactivated by hand afterwards — and frequently isn't. Our logic does the opposite: it stays inside MPC, exhausts every available corrective handle first, and only escalates to the DCS as the last step.
Measured Results from the End of Campaign
The logic was deployed during the final two weeks of the campaign — frozen beet, very cold weather, degraded cossette geometry. These are the worst conditions an extraction tower sees. The figures below come from measured plant data over that window.
| Outcome metric | Before the logic | With the logic (test window) |
|---|---|---|
| Manual operator actions per pressure event | Many adjustments per event | Zero |
| Pressure events handled automatically | — | All events during the 2-week test window |
| Slicing reductions needed during events | Frequent, sometimes full stoppages | Not needed in most cases |
| Tower emptying events | Possible in worst cases | None |
| DCS transfers triggered for pressure | Occasional | None |
What These Outcomes Mean
Pressure excursions were a regular feature of those last weeks. The logic absorbed every one automatically, within its short correction cycles. Three observations stand out beyond the table above:
- Operators didn't notice. No detectable disturbance on the HMI trend, no phone calls, no shift handover notes about pressure.
- MPC stayed in control. Every event ended with a smooth handback — no manual reactivation, no production dip after recovery.
- Slicing was preserved. In most events the logic resolved the pressure rise without needing to reduce the upstream slicing rate, so production throughput continued through the excursion.
Optimisation Headroom Unlocked
The harder-to-quantify benefit, and the most valuable in the long run, is optimisation headroom. With a reliable pressure-protection net, MPC can run the tower closer to its true production limits — higher throughput, tighter operating points — because the safety case for pressure no longer depends on operator vigilance. Margin previously held in reserve becomes available as yield and capacity.
Deployment: Two Phases, Low Risk
The logic deploys as a configurable module inside the existing MPC application. No DCS rewrite, no new hardware. The rollout follows two phases.
Phase 1 — Configuration and Live Calibration
Initial values for the operational and engineering thresholds, the stabilisation wait time, and the correction magnitudes are configured based on the plant's historical pressure data and known mechanical limits. Defaults from the reference plant are a useful starting point but should always be reviewed against site-specific conditions. The logic is then commissioned during the first weeks of campaign, where real pressure events confirm whether the initial settings are correct. If thresholds are too high or correction magnitudes too small, the logic will activate too late — re-tuning typically takes one iteration. This is a normal commissioning step, not a failure.
Phase 2 — Continuous Operation
Once tuned, the logic runs continuously alongside the optimisation layer, handling pressure events automatically. Operators retain visibility through the informatory alarm but no longer carry the workload. The same configuration can be replicated to other extraction lines, with independent threshold tuning per unit.
Part of the Sucrosphere MPC Package
This pressure protection logic isn't a bolt-on — it ships as an integral part of our MPC solution, deployed alongside the optimisation layer and our smart sensors (VSS for cossette quality, NIRS for stream composition) in every installation. If your operators are still managing pressure excursions by hand, we'd be glad to walk through how the full package would deploy in your tower architecture and DCS.
Frequently Asked Questions
Does the logic replace existing pressure interlocks in the DCS?
No. Hardware-level safety interlocks remain in place and unchanged. The logic operates as a supervisory layer inside MPC, intervening earlier than the DCS interlock would, so the interlock effectively never has to fire. Think of it as a soft barrier in front of the hard one.
What if MPC itself goes down during a pressure event?
Standard MPC fallback behaviour applies — control reverts to the DCS, which holds last set-points and triggers existing alarms. The logic doesn't change the plant's failure mode; it simply prevents most events from reaching that mode in the first place.
How long does calibration take?
In our case, one iteration. After observing one event where the logic activated too late, the engineering threshold was tightened and the correction magnitudes increased. The logic ran without further intervention for the rest of the campaign. Plan for the first one or two events to inform tuning, then expect stable operation.
Can the same logic be reused on another tower with different geometry?
Yes. All thresholds and correction magnitudes are configurable per unit. Different towers will have different operating bounds, different mixer moment limits, and different correction magnitudes — but the algorithm is the same. The reference plant configuration is a useful starting point that gets re-tuned to each unit during commissioning.
What about operator confidence — do they trust automation taking over pressure?
Trust is built by the informatory alarm: operators see when the logic is working, and over a campaign they observe that events resolve without needing them. With a transparent escalation path to a slicing-reduction alarm and ultimately DCS handover, awareness is retained without the workload — operators reclaim attention for other parts of the process.